System Design 1
What is system Design?
Section titled “What is system Design?”System design is the process of defining a system’s architecture, components, modules, interfaces, and data to meet specific requirements, essentially creating a detailed blueprint for building software or hardware systems that are efficient, scalable, and reliable
It’s the crucial step between understanding user needs (requirements analysis) and writing code (implementation), focusing on high-level structure, interactions, and non-functional aspects like performance, security, and maintainability, rather than the code itself
How to approach system design?
Section titled “How to approach system design?”System Design is extremely practical and there is a structured way to tackle the situations.
- Understand the problem statement
- Break it down into components/features (essential). e,g, Social media Feed, Notification
- Dissect each component into sub component (if required). e.g. Aggregator and Recommendation generator in Feed.
- Now for each sub component look into
- Database and Caching
- Scaling & Fault Tolerance
- Async processing (Delegation)
- Communication
How do you know that you have built a good system?
Section titled “How do you know that you have built a good system?”Every system is “infinitely” buildable and hence knowing when to stop the evolution is important.
- You broke your system into components
- Every component has a clear set of responsibilities (Mutually Exclusive)
- For each component, you’ve slight technical details figured out
- Database and Caching
- Scaling & Fault Tolerance
- Async processing (Delegation)
- Communication
- Each component (in isolation) is
- scalable → horizontally scalable
- fault tolerant → plan for recovery in case of a failure
- Data and the server it self should auto recover
- available → component functions even when some component “fails”
Relational Databases
Section titled “Relational Databases”Databases are most critical component of any system. They make or break a system.
Data is stored & represented in rows and columns. You pick relational databases far relations and acid.
Properties A - Atomicity C - Consistency I - Isolation D - Durability
A - Atomicity
Section titled “A - Atomicity”All statements within a transaction takes effect or none of them take effect.
C - Consistency
Section titled “C - Consistency”All data in the database should conform to the rules, no constraints are violated using constraints, cascades, triggers Foreign key checks do not allow you to delete parent if child exists (configurable though) e.g. Cascade
I -Isolation
Section titled “I -Isolation”Concurrent transactions should not interfere with each other. This is achieved through various levels of isolation (Read uncommitted, Read committed, Repeatable read, Serialisable) depending on the needs of the application.
D - Durability
Section titled “D - Durability”when transaction commits, the changes outlives outages.
Database Isolation Levels
Section titled “Database Isolation Levels”Database isolation levels refer to the degree to which a transaction must be isolated from the data modifications made by any other transactions.
Isolation levels dictate how much one transaction knows about the other
There are four isolation levels defined by the SQL standard. Each level defines the degree to which one transaction must be isolated from the resource modifications made by other transactions.
Read uncommitted
Section titled “Read uncommitted”This is the lowest isolation level, and it allows a transaction to read data changes that have not yet been committed by other transactions. This can lead to “dirty reads,” where a transaction reads data that is later rolled back.
e.g. Transaction A reads data modified by transaction B before B commits.
Read committed
Section titled “Read committed”This level guarantees that a transaction will only read data that has been committed. It prevents dirty reads but allows for non-repeatable reads, where the same query can return different results at different times.
e.g. Transaction A reads data committed by transaction B.
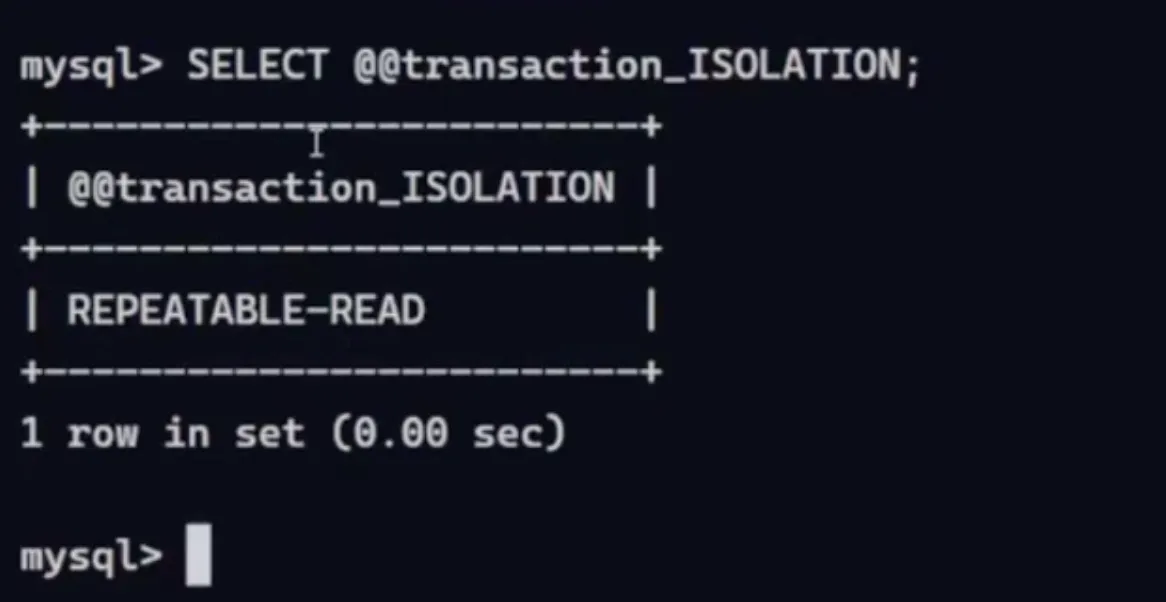
Repeatable read (Default)
Section titled “Repeatable read (Default)”This level ensures that all reads within a transaction see the same data. However, it can still lead to phantom reads, where new rows are added or removed during a transaction.
e.g. Transaction A reads data that was visible at the start of transaction A, even if transaction B has committed changes in between.
What is Phantom read?
Section titled “What is Phantom read?”Phantom reads occur when one transaction reads a set of rows and then another transaction inserts or deletes rows that match the search criteria of the first transaction.
This causes the first transaction to see rows that did not exist when it started, leading to inconsistent results.
Serializable
Section titled “Serializable”This is the highest isolation level. It guarantees that transactions are isolated from each other. In this level, transactions are executed serially, preventing dirty reads, non-repeatable reads, and phantom reads.
This will reduce the throughput of the system and things can be a lot slower
e.g. Transaction A is processed as if no other transactions were running concurrently, Even if they are running it will wait until the rollback or commit of it.
Scaling Databases
Section titled “Scaling Databases”- These techniques are applicable to most databases out there relational and non- relational
Vertical Scaling
Section titled “Vertical Scaling”- add more CPU, RAM, Disk to the database
- requires downtime during reboot
- gives you ability to handle “scale”, more load
Horizontal Scaling
Section titled “Horizontal Scaling”Read Replicas
Section titled “Read Replicas”- when read: write is 90:10
- You move reads to other database so that “master” is free to do writes
- API Servers should know which DB to connect to get things done. So that it will connect two connections. One with Primary for write and another with replica for read.
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-B' id='L-A-B-0' d='M239.734%2c16.5L249.608%2c16.5C259.482%2c16.5%2c279.229%2c16.5%2c298.122%2c18.877C317.016%2c21.254%2c335.055%2c26.009%2c344.074%2c28.386L353.094%2c30.763'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-C LE-A' id='L-C-A-0' d='M85.464%2c30.25L90.879%2c27.958C96.294%2c25.667%2c107.123%2c21.083%2c115.822%2c18.792C124.52%2c16.5%2c131.086%2c16.5%2c134.37%2c16.5L137.653%2c16.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-C LE-B' id='L-C-B-0' d='M85.464%2c63.25L90.879%2c65.542C96.294%2c67.833%2c107.123%2c72.417%2c124.77%2c74.708C142.417%2c77%2c166.88%2c77%2c197.051%2c77C227.221%2c77%2c263.099%2c77%2c290.057%2c74.623C317.016%2c72.246%2c335.055%2c67.491%2c344.074%2c65.114L353.094%2c62.737'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg transform='translate(298.9765625%2c 16.5)' class='edgeLabel'%3e%3cg transform='translate(-34.2421875%2c -9)' class='label'%3e%3cforeignObject height='18' width='68.484375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3ereplicates%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(191.34375%2c 77)' class='edgeLabel'%3e%3cg transform='translate(-33.3515625%2c -9)' class='label'%3e%3cforeignObject height='18' width='66.703125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eread-only%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(191.34375%2c 16.5)' data-id='A' data-node='true' id='flowchart-A-0' class='node default default flowchart-label'%3e%3crect height='33' width='96.78125' y='-16.5' x='-48.390625' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-40.890625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='81.78125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3ePrimary DB%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(413.75%2c 46.75)' data-id='B' data-node='true' id='flowchart-B-1' class='node default default flowchart-label'%3e%3crect height='33' width='111.0625' y='-16.5' x='-55.53125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-48.03125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='96.0625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eRead Replica%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(46.4765625%2c 46.75)' data-id='C' data-node='true' id='flowchart-C-2' class='node default default flowchart-label'%3e%3crect height='33' width='92.953125' y='-16.5' x='-46.4765625' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-38.9765625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='77.953125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eApp Writes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Replication
Section titled “Replication”Changes on one database (Master) needs to be sent to Replica to maintain consistency
Synchronous Replication
Section titled “Synchronous Replication”The main database waits for changes to be written to the replica before acknowledging the commit. Offers higher consistency but can impact performance.
%3bfill:%23ECECFF%3b%7d%23mermaid-0 text.actor%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .actor-line%7bstroke:grey%3b%7d%23mermaid-0 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-0 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-0 %23arrowhead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .sequenceNumber%7bfill:white%3b%7d%23mermaid-0 %23sequencenumber%7bfill:%23333%3b%7d%23mermaid-0 %23crosshead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .labelBox%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-0 .labelText%2c%23mermaid-0 .labelText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .loopText%2c%23mermaid-0 .loopText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-0 .note%7bstroke:%23aaaa33%3bfill:%23fff5ad%3b%7d%23mermaid-0 .noteText%2c%23mermaid-0 .noteText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-0 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23ECECFF%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-0 .actor-man line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-0 .actor-man circle%2c%23mermaid-0 line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3bstroke-width:2px%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol height='24' width='24' id='computer'%3e%3cpath d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol clip-rule='evenodd' fill-rule='evenodd' id='database'%3e%3cpath d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol height='24' width='24' id='clock'%3e%3cpath d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='7.9' id='arrowhead'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker refY='4.5' refX='4' orient='auto' markerHeight='8' markerWidth='15' id='crosshead'%3e%3cpath style='stroke-dasharray: 0%2c 0%3b' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' stroke-width='1pt' stroke='black' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='15.5' id='filled-head'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='40' markerWidth='60' refY='15' refX='15' id='sequencenumber'%3e%3ccircle r='6' cy='15' cx='15'/%3e%3c/marker%3e%3c/defs%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='80' x='174'%3eWrite request%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='109' x2='271' y1='109' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='124' x='395'%3eReplicate change (sync)%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='153' x2='513' y1='153' x1='276'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='168' x='398'%3eAcknowledge%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='197' x2='279' y1='197' x1='516'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='212' x='177'%3eCommit confirmed%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='241' x2='79' y1='241' x1='274'/%3e%3c/svg%3e)
Asynchronous Replication
Section titled “Asynchronous Replication”The main database does not wait for changes to be written to the replica before acknowledging the commit. Offers higher performance but can potentially lead to data inconsistency.
%3bfill:%23ECECFF%3b%7d%23mermaid-0 text.actor%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .actor-line%7bstroke:grey%3b%7d%23mermaid-0 .messageLine0%7bstroke-width:1.5%3bstroke-dasharray:none%3bstroke:%23333%3b%7d%23mermaid-0 .messageLine1%7bstroke-width:1.5%3bstroke-dasharray:2%2c2%3bstroke:%23333%3b%7d%23mermaid-0 %23arrowhead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .sequenceNumber%7bfill:white%3b%7d%23mermaid-0 %23sequencenumber%7bfill:%23333%3b%7d%23mermaid-0 %23crosshead path%7bfill:%23333%3bstroke:%23333%3b%7d%23mermaid-0 .messageText%7bfill:%23333%3bstroke:none%3b%7d%23mermaid-0 .labelBox%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-0 .labelText%2c%23mermaid-0 .labelText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .loopText%2c%23mermaid-0 .loopText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .loopLine%7bstroke-width:2px%3bstroke-dasharray:2%2c2%3bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3b%7d%23mermaid-0 .note%7bstroke:%23aaaa33%3bfill:%23fff5ad%3b%7d%23mermaid-0 .noteText%2c%23mermaid-0 .noteText%26gt%3btspan%7bfill:black%3bstroke:none%3b%7d%23mermaid-0 .activation0%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation1%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .activation2%7bfill:%23f4f4f4%3bstroke:%23666%3b%7d%23mermaid-0 .actorPopupMenu%7bposition:absolute%3b%7d%23mermaid-0 .actorPopupMenuPanel%7bposition:absolute%3bfill:%23ECECFF%3bbox-shadow:0px 8px 16px 0px rgba(0%2c0%2c0%2c0.2)%3bfilter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4))%3b%7d%23mermaid-0 .actor-man line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3b%7d%23mermaid-0 .actor-man circle%2c%23mermaid-0 line%7bstroke:hsl(259.6261682243%2c 59.7765363128%25%2c 87.9019607843%25)%3bfill:%23ECECFF%3bstroke-width:2px%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg/%3e%3cdefs%3e%3csymbol height='24' width='24' id='computer'%3e%3cpath d='M2 2v13h20v-13h-20zm18 11h-16v-9h16v9zm-10.228 6l.466-1h3.524l.467 1h-4.457zm14.228 3h-24l2-6h2.104l-1.33 4h18.45l-1.297-4h2.073l2 6zm-5-10h-14v-7h14v7z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol clip-rule='evenodd' fill-rule='evenodd' id='database'%3e%3cpath d='M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258 20.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3csymbol height='24' width='24' id='clock'%3e%3cpath d='M12 2c5.514 0 10 4.486 10 10s-4.486 10-10 10-10-4.486-10-10 4.486-10 10-10zm0-2c-6.627 0-12 5.373-12 12s5.373 12 12 12 12-5.373 12-12-5.373-12-12-12zm5.848 12.459c.202.038.202.333.001.372-1.907.361-6.045 1.111-6.547 1.111-.719 0-1.301-.582-1.301-1.301 0-.512.77-5.447 1.125-7.445.034-.192.312-.181.343.014l.985 6.238 5.394 1.011z' transform='scale(.5)'/%3e%3c/symbol%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='7.9' id='arrowhead'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker refY='4.5' refX='4' orient='auto' markerHeight='8' markerWidth='15' id='crosshead'%3e%3cpath style='stroke-dasharray: 0%2c 0%3b' d='M 1%2c2 L 6%2c7 M 6%2c2 L 1%2c7' stroke-width='1pt' stroke='black' fill='none'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='28' markerWidth='20' refY='7' refX='15.5' id='filled-head'%3e%3cpath d='M 18%2c7 L9%2c13 L14%2c7 L9%2c1 Z'/%3e%3c/marker%3e%3c/defs%3e%3cdefs%3e%3cmarker orient='auto' markerHeight='40' markerWidth='60' refY='15' refX='15' id='sequencenumber'%3e%3ccircle r='6' cy='15' cx='15'/%3e%3c/marker%3e%3c/defs%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='80' x='174'%3eWrite request%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='109' x2='271' y1='109' x1='76'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='124' x='177'%3eCommit confirmed%3c/text%3e%3cline style='stroke-dasharray: 3%2c 3%3b fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine1' y2='153' x2='79' y1='153' x1='274'/%3e%3ctext style='font-family: arial%2c sans-serif%3b font-size: 16px%3b font-weight: 400%3b' dy='1em' class='messageText' alignment-baseline='middle' dominant-baseline='middle' text-anchor='middle' y='168' x='431'%3eReplicate change (async%2c delayed)%3c/text%3e%3cline style='fill: none%3b' marker-end='url(%23arrowhead)' stroke='none' stroke-width='2' class='messageLine0' y2='197' x2='586' y1='197' x1='276'/%3e%3c/svg%3e)
- In this Primary DB can send the data to be committed by replica
- or replica periodically polls the data from master both way it can be implemented.
- All the DB providers have this functionality just need to configure it.
Sharding
Section titled “Sharding”What if we get huge amount of write in that case sharding helps
- Partitioning data across multiple databases.
- Because one node cannot handle the data load we split it into multiple exclusive subsets writes on a particular row/document will go to one particular shard.
- API server needs to know whom to connect to, to get things done.
- Note: some databases has a proxy that takes care of routing
- Each shard can have its own replica (if needed)
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg id='subGraph0' class='cluster default flowchart-label'%3e%3crect height='350.5394172668457' width='121.046875' y='0' x='90.796875' ry='0' rx='0' style=''/%3e%3cg transform='translate(116.6328125%2c 0)' class='cluster-label'%3e%3cforeignObject height='18' width='69.375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eData Split%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-API LE-S1' id='L-API-S1-0' d='M27.197%2c158.77L33.63%2c143.156C40.064%2c127.543%2c52.93%2c96.317%2c63.53%2c80.703C74.13%2c65.09%2c82.464%2c65.09%2c89.914%2c65.09C97.364%2c65.09%2c103.93%2c65.09%2c107.214%2c65.09L110.497%2c65.09'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-API LE-S2' id='L-API-S2-0' d='M40.797%2c175.27L44.964%2c175.27C49.13%2c175.27%2c57.464%2c175.27%2c65.797%2c175.27C74.13%2c175.27%2c82.464%2c175.27%2c89.914%2c175.27C97.364%2c175.27%2c103.93%2c175.27%2c107.214%2c175.27L110.497%2c175.27'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-API LE-S3' id='L-API-S3-0' d='M27.197%2c191.77L33.63%2c207.383C40.064%2c222.996%2c52.93%2c254.223%2c63.53%2c269.836C74.13%2c285.45%2c82.464%2c285.45%2c89.914%2c285.45C97.364%2c285.45%2c103.93%2c285.45%2c107.214%2c285.45L110.497%2c285.45'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(151.3203125%2c 65.08990287780762)' data-id='S1' data-node='true' id='flowchart-S1-1' class='node default default flowchart-label'%3e%3cpath transform='translate(-35.5234375%2c-30.08990196859807)' d='M 0%2c9.059934645732048 a 35.5234375%2c9.059934645732048 0%2c0%2c0 71.046875 0 a 35.5234375%2c9.059934645732048 0%2c0%2c0 -71.046875 0 l 0%2c42.05993464573205 a 35.5234375%2c9.059934645732048 0%2c0%2c0 71.046875 0 l 0%2c-42.05993464573205' style=''/%3e%3cg transform='translate(-28.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='56.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eShard 1%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(151.3203125%2c 175.26970863342285)' data-id='S2' data-node='true' id='flowchart-S2-3' class='node default default flowchart-label'%3e%3cpath transform='translate(-35.5234375%2c-30.08990196859807)' d='M 0%2c9.059934645732048 a 35.5234375%2c9.059934645732048 0%2c0%2c0 71.046875 0 a 35.5234375%2c9.059934645732048 0%2c0%2c0 -71.046875 0 l 0%2c42.05993464573205 a 35.5234375%2c9.059934645732048 0%2c0%2c0 71.046875 0 l 0%2c-42.05993464573205' style=''/%3e%3cg transform='translate(-28.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='56.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eShard 2%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(151.3203125%2c 285.4495143890381)' data-id='S3' data-node='true' id='flowchart-S3-5' class='node default default flowchart-label'%3e%3cpath transform='translate(-35.5234375%2c-30.08990196859807)' d='M 0%2c9.059934645732048 a 35.5234375%2c9.059934645732048 0%2c0%2c0 71.046875 0 a 35.5234375%2c9.059934645732048 0%2c0%2c0 -71.046875 0 l 0%2c42.05993464573205 a 35.5234375%2c9.059934645732048 0%2c0%2c0 71.046875 0 l 0%2c-42.05993464573205' style=''/%3e%3cg transform='translate(-28.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='56.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eShard 3%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(20.3984375%2c 175.26970863342285)' data-id='API' data-node='true' id='flowchart-API-0' class='node default default flowchart-label'%3e%3crect height='33' width='40.796875' y='-16.5' x='-20.3984375' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-12.8984375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='25.796875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eAPI%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Advantages of sharding
- Handle large Reads and Writes
- Increase overall storage capacity
- Higher availability
Disadvantages of sharding
- operationally complex
- cross-shard queries expensive
Sharding : Method of distributing data across multiple machines
Partioning: splitting a subset of data within the same instance or multiple.
Overall, a database is sharded while the data is partitioned (split across).
Diagram showing a 100 GB dataset split into 3 partitions distributed across 2 shards (40, 40, 20 GB):
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-P1' id='L-A-P1-0' d='M82.199%2c83L94.139%2c71.917C106.08%2c60.833%2c129.962%2c38.667%2c145.186%2c27.583C160.41%2c16.5%2c166.977%2c16.5%2c170.26%2c16.5L173.544%2c16.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-P2' id='L-A-P2-0' d='M128.844%2c99.5L133.01%2c99.5C137.177%2c99.5%2c145.51%2c99.5%2c152.96%2c99.5C160.41%2c99.5%2c166.977%2c99.5%2c170.26%2c99.5L173.544%2c99.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-P3' id='L-A-P3-0' d='M82.199%2c116L94.139%2c127.083C106.08%2c138.167%2c129.962%2c160.333%2c145.186%2c171.417C160.41%2c182.5%2c166.977%2c182.5%2c170.26%2c182.5L173.544%2c182.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-P1 LE-S1' id='L-P1-S1-0' d='M325.469%2c16.5L329.635%2c16.5C333.802%2c16.5%2c342.135%2c16.5%2c351.65%2c20.167C361.165%2c23.834%2c371.861%2c31.169%2c377.209%2c34.836L382.558%2c38.503'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-P2 LE-S1' id='L-P2-S1-0' d='M325.469%2c99.5L329.635%2c99.5C333.802%2c99.5%2c342.135%2c99.5%2c351.65%2c95.833C361.165%2c92.166%2c371.861%2c84.831%2c377.209%2c81.164L382.558%2c77.497'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-P3 LE-S2' id='L-P3-S2-0' d='M325.469%2c182.5L329.635%2c182.5C333.802%2c182.5%2c342.135%2c182.5%2c349.585%2c182.5C357.035%2c182.5%2c363.602%2c182.5%2c366.885%2c182.5L370.169%2c182.5'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(64.421875%2c 99.5)' data-id='A' data-node='true' id='flowchart-A-0' class='node default default flowchart-label'%3e%3crect height='33' width='128.84375' y='-16.5' x='-64.421875' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-56.921875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='113.84375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e100 GB Dataset%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(252.15625%2c 16.5)' data-id='P1' data-node='true' id='flowchart-P1-1' class='node default default flowchart-label'%3e%3crect height='33' width='146.625' y='-16.5' x='-73.3125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-65.8125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='131.625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3ePartition 1 - 40 GB%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(252.15625%2c 99.5)' data-id='P2' data-node='true' id='flowchart-P2-3' class='node default default flowchart-label'%3e%3crect height='33' width='146.625' y='-16.5' x='-73.3125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-65.8125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='131.625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3ePartition 2 - 40 GB%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(252.15625%2c 182.5)' data-id='P3' data-node='true' id='flowchart-P3-5' class='node default default flowchart-label'%3e%3crect height='33' width='146.625' y='-16.5' x='-73.3125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-65.8125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='131.625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3ePartition 3 - 20 GB%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(410.9921875%2c 58)' data-id='S1' data-node='true' id='flowchart-S1-7' class='node default default flowchart-label'%3e%3crect height='33' width='71.046875' y='-16.5' x='-35.5234375' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-28.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='56.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eShard 1%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(410.9921875%2c 182.5)' data-id='S2' data-node='true' id='flowchart-S2-11' class='node default default flowchart-label'%3e%3crect height='33' width='71.046875' y='-16.5' x='-35.5234375' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-28.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='56.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eShard 2%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Partioning
Section titled “Partioning”- Horizontal Partitioning (most common)
- Some of the table rows put in one DB and other rows in other DB
- Vertical Partitioning
- these 3 tables in DB1 and these 4 tables in another DB.2
- It is like moving from monolith to microservice
deciding which one to pick depends on load, use case, and access pattern.
Non - Relational DB
Section titled “Non - Relational DB”It is a very broad generalisation of databases that are non-relational (MysqL, PostgresqL, etc) But this does not mean all non-relational databases are similar.
Most non-relational databases shard out-of-the box.
Important DB types
Section titled “Important DB types”Document DB
Section titled “Document DB”- MongoDB, Elasticsearch.
- Mostly JSON based
- Support complex queries
- Partial updates to document is possible.
- Like no need to get whole record and edit and put it back
Key Value Stores
Section titled “Key Value Stores”- (Redis, DynamoDB, Acrospike)
- Extremely simple databases | Limitied functionalities
- GET (K)
- PUT (K,v)
- DEL (K)
- Does not support complex queries (aggregations)
- Can be heavily sharded and partitioned
- Use case: profile data, order data, auth data.
Graph DB
Section titled “Graph DB”- (Neo4j, Neptune, Dgraph)
- What if our graph data structure had a database
- it stores data that are represented as nodes, edges, and relations
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-User1 LE-User2' id='L-User1-User2-0' d='M47.142%2c51.985L58.102%2c56.22C69.061%2c60.454%2c90.98%2c68.922%2c113.949%2c73.156C136.918%2c77.391%2c160.938%2c77.391%2c172.948%2c77.391L184.958%2c77.391'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-User1 LE-Post1' id='L-User1-Post1-0' d='M47.142%2c34.405L58.102%2c30.171C69.061%2c25.937%2c90.98%2c17.468%2c118.897%2c13.234C146.815%2c9%2c180.732%2c9%2c211.983%2c9C243.234%2c9%2c271.82%2c9%2c293.719%2c12.631C315.618%2c16.262%2c330.83%2c23.523%2c338.436%2c27.154L346.042%2c30.785'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-User2 LE-Post1' id='L-User2-Post1-0' d='M239.039%2c77.391L249.267%2c77.391C259.495%2c77.391%2c279.951%2c77.391%2c297.784%2c73.76C315.618%2c70.129%2c330.83%2c62.867%2c338.436%2c59.237L346.042%2c55.606'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-Post1 LE-Comment1' id='L-Post1-Comment1-0' d='M395.547%2c43.195L402.456%2c43.195C409.365%2c43.195%2c423.182%2c43.195%2c436.117%2c43.195C449.051%2c43.195%2c461.102%2c43.195%2c467.128%2c43.195L473.153%2c43.195'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg transform='translate(112.8984375%2c 77.390625)' class='edgeLabel'%3e%3cg transform='translate(-39.1171875%2c -9)' class='label'%3e%3cforeignObject height='18' width='78.234375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eFOLLOWS%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(214.6484375%2c 9)' class='edgeLabel'%3e%3cg transform='translate(-37.6328125%2c -9)' class='label'%3e%3cforeignObject height='18' width='75.265625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eCREATED%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(300.40625%2c 77.390625)' class='edgeLabel'%3e%3cg transform='translate(-23.125%2c -9)' class='label'%3e%3cforeignObject height='18' width='46.25'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eLIKED%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(437%2c 43.1953125)' class='edgeLabel'%3e%3cg transform='translate(-16.453125%2c -9)' class='label'%3e%3cforeignObject height='18' width='32.90625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eHAS%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(24.390625%2c 43.1953125)' data-id='User1' data-node='true' id='flowchart-User1-0' class='node default default flowchart-label'%3e%3ccircle height='33' width='48.78125' r='24.390625' ry='0' rx='0' style=''/%3e%3cg transform='translate(-16.890625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='33.78125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eUser%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(214.6484375%2c 77.390625)' data-id='User2' data-node='true' id='flowchart-User2-1' class='node default default flowchart-label'%3e%3ccircle height='33' width='48.78125' r='24.390625' ry='0' rx='0' style=''/%3e%3cg transform='translate(-16.890625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='33.78125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eUser%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(372.0390625%2c 43.1953125)' data-id='Post1' data-node='true' id='flowchart-Post1-2' class='node default default flowchart-label'%3e%3ccircle height='33' width='47.015625' r='23.5078125' ry='0' rx='0' style=''/%3e%3cg transform='translate(-16.0078125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='32.015625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3ePost%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(520.6328125%2c 43.1953125)' data-id='Comment1' data-node='true' id='flowchart-Comment1-3' class='node default default flowchart-label'%3e%3ccircle height='33' width='84.359375' r='42.1796875' ry='0' rx='0' style=''/%3e%3cg transform='translate(-34.6796875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='69.359375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eComment%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
- Great for running complex graph algorithms
- Powerful to model Social Networks, Recommendations & Fraud Detection
How to pick right database?
Section titled “How to pick right database?”Common Misconception: Picking Non-relational DB because relational Databases do not scale.
Why non-relational DBs scale?
- There are no relations and constraints
- Data is modelled to be sharded
if we relax the above on relational DB, we can scale
- do not use Foreign Key check
- do not use cross shard transaction
- do manual sharding
Does this mean, no OB is different? No!! every single database has some peculiar properties and guarantees and if you need those, you pick that DB
How does this help in designing system?
Section titled “How does this help in designing system?”While designing any system, do not jump to a particular DB right away
- understand what data you are storing
- understand how much of data you will be storing
- understand how you will be accessing the data
- What kind of queries you will be firing
- any special feature you expect eg: Expiration
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-B' id='L-A-B-0' d='M469.695%2c33L469.695%2c37.167C469.695%2c41.333%2c469.695%2c49.667%2c469.761%2c57.2C469.827%2c64.734%2c469.959%2c71.467%2c470.025%2c74.834L470.091%2c78.201'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-B LE-C' id='L-B-C-0' d='M389.384%2c263.298L358.058%2c282.35C326.731%2c301.402%2c264.079%2c339.506%2c232.823%2c363.424C201.567%2c387.343%2c201.708%2c397.076%2c201.778%2c401.943L201.849%2c406.81'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-C LE-R1' id='L-C-R1-0' d='M129.403%2c689.977L116.779%2c707.648C104.155%2c725.318%2c78.908%2c760.659%2c66.284%2c816.409C53.66%2c872.159%2c53.66%2c948.318%2c53.66%2c1024.477C53.66%2c1100.635%2c53.66%2c1176.794%2c55.934%2c1239.126C58.207%2c1301.457%2c62.755%2c1349.961%2c65.028%2c1374.213L67.302%2c1398.465'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-C LE-D' id='L-C-D-0' d='M261.197%2c703.229L269.062%2c718.69C276.927%2c734.152%2c292.657%2c765.076%2c300.598%2c790.173C308.539%2c815.27%2c308.692%2c834.54%2c308.768%2c844.175L308.845%2c853.81'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-D LE-R1' id='L-D-R1-0' d='M248.372%2c1130.329L236.501%2c1150.766C224.631%2c1171.204%2c200.89%2c1212.078%2c174.229%2c1256.892C147.568%2c1301.706%2c117.988%2c1350.458%2c103.198%2c1374.835L88.409%2c1399.211'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-D LE-E' id='L-D-E-0' d='M345.441%2c1154.289L350.03%2c1170.733C354.618%2c1187.177%2c363.795%2c1220.065%2c368.455%2c1241.376C373.114%2c1262.687%2c373.255%2c1272.42%2c373.325%2c1277.287L373.396%2c1282.154'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-E LE-R2' id='L-E-R2-0' d='M294.279%2c1492.838L270.517%2c1511.62C246.755%2c1530.402%2c199.231%2c1567.967%2c175.469%2c1620.354C151.707%2c1672.742%2c151.707%2c1739.953%2c151.707%2c1807.164C151.707%2c1874.375%2c151.707%2c1941.586%2c153.31%2c1981.502C154.913%2c2021.418%2c158.119%2c2034.039%2c159.722%2c2040.349L161.324%2c2046.66'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-E LE-F' id='L-E-F-0' d='M473.786%2c1471.718L527.2%2c1494.02C580.614%2c1516.322%2c687.442%2c1560.927%2c740.926%2c1588.096C794.411%2c1615.265%2c794.552%2c1624.998%2c794.622%2c1629.865L794.693%2c1634.732'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-F LE-R2' id='L-F-R2-0' d='M710.024%2c1890.552L689.706%2c1910.259C669.389%2c1929.967%2c628.753%2c1969.382%2c543.752%2c1998.224C458.752%2c2027.067%2c329.387%2c2045.338%2c264.704%2c2054.473L200.021%2c2063.608'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-F LE-R3' id='L-F-R3-0' d='M859.645%2c1910.421L869.966%2c1926.817C880.287%2c1943.213%2c900.929%2c1976.005%2c913.009%2c1997.237C925.088%2c2018.47%2c928.607%2c2028.143%2c930.366%2c2032.98L932.125%2c2037.816'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-B LE-G' id='L-B-G-0' d='M555.563%2c258.742L593.274%2c278.553C630.985%2c298.364%2c706.406%2c337.987%2c744.117%2c392.664C781.828%2c447.341%2c781.828%2c517.073%2c781.828%2c586.805C781.828%2c656.536%2c781.828%2c726.268%2c781.899%2c766.001C781.969%2c805.734%2c782.11%2c815.467%2c782.181%2c820.334L782.251%2c825.201'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-G LE-R4' id='L-G-R4-0' d='M712.608%2c1149.733L702.864%2c1166.937C693.12%2c1184.14%2c673.632%2c1218.546%2c663.888%2c1261.498C654.145%2c1304.449%2c654.145%2c1355.946%2c654.145%2c1381.694L654.145%2c1407.442'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-G LE-H' id='L-G-H-0' d='M852.048%2c1149.733L861.625%2c1166.937C871.203%2c1184.14%2c890.357%2c1218.546%2c900.01%2c1244.917C909.664%2c1271.288%2c909.816%2c1289.623%2c909.892%2c1298.791L909.968%2c1307.958'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-H LE-R5' id='L-H-R5-0' d='M827.89%2c1464.105L771.278%2c1487.676C714.665%2c1511.247%2c601.44%2c1558.389%2c544.827%2c1610.432C488.215%2c1662.476%2c488.215%2c1719.42%2c488.215%2c1747.892L488.215%2c1776.364'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-H LE-I' id='L-H-I-0' d='M986.244%2c1469.994L1029.101%2c1492.584C1071.957%2c1515.173%2c1157.67%2c1560.352%2c1200.602%2c1591.738C1243.534%2c1623.124%2c1243.686%2c1640.717%2c1243.761%2c1649.513L1243.837%2c1658.31'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-I LE-R6' id='L-I-R6-0' d='M1257.845%2c1937.756L1259.042%2c1949.596C1260.238%2c1961.437%2c1262.631%2c1985.117%2c1263.827%2c2001.74C1265.023%2c2018.364%2c1265.023%2c2027.93%2c1265.023%2c2032.714L1265.023%2c2037.497'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-I LE-R3' id='L-I-R3-0' d='M1164.625%2c1872.461L1136.647%2c1895.184C1108.668%2c1917.907%2c1052.711%2c1963.352%2c1020.224%2c1991.084C987.737%2c2018.817%2c978.72%2c2028.837%2c974.212%2c2033.847L969.703%2c2038.857'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(201.42578125%2c 377.609375)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(53.66015625%2c 1024.4765625)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(308.38671875%2c 796)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(177.1484375%2c 1252.953125)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(372.97265625%2c 1252.953125)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(151.70703125%2c 1807.1640625)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(794.26953125%2c 1605.53125)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(588.1171875%2c 2008.796875)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(921.5703125%2c 2008.796875)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(781.828125%2c 586.8046875)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(654.14453125%2c 1252.953125)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(909.51171875%2c 1252.953125)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(488.21484375%2c 1605.53125)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1243.3828125%2c 1605.53125)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1265.0234375%2c 2008.796875)' class='edgeLabel'%3e%3cg transform='translate(-13.0546875%2c -9)' class='label'%3e%3cforeignObject height='18' width='26.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eYes%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(996.75390625%2c 2008.796875)' class='edgeLabel'%3e%3cg transform='translate(-10.2265625%2c -9)' class='label'%3e%3cforeignObject height='18' width='20.453125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eNo%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(469.6953125%2c 16.5)' data-id='A' data-node='true' id='flowchart-A-0' class='node default default flowchart-label'%3e%3crect height='33' width='199.109375' y='-16.5' x='-99.5546875' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-92.0546875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='184.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eStart: Choose a Database%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(469.6953125%2c 213.3046875)' data-id='B' data-node='true' id='flowchart-B-1' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-130.3046875%2c130.3046875)' class='label-container' points='130.3046875%2c0 260.609375%2c-130.3046875 130.3046875%2c-260.609375 0%2c-130.3046875'/%3e%3cg transform='translate(-106.3046875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='212.609375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eCan data fit on a single node%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(201.42578125%2c 586.8046875)' data-id='C' data-node='true' id='flowchart-C-3' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-175.1953125%2c175.1953125)' class='label-container' points='175.1953125%2c0 350.390625%2c-175.1953125 175.1953125%2c-350.390625 0%2c-175.1953125'/%3e%3cg transform='translate(-151.1953125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='302.390625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eNeed strong consistency and correctness%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(70.1875%2c 1429.2421875)' data-id='R1' data-node='true' id='flowchart-R1-5' class='node default default flowchart-label'%3e%3crect height='51' width='140.375' y='-25.5' x='-70.1875' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-62.6875%2c -18)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='36' width='125.375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eRelational DB%3cbr /%3ePostgres%2c MySQL%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(308.38671875%2c 1024.4765625)' data-id='D' data-node='true' id='flowchart-D-7' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-165.8671875%2c165.8671875)' class='label-container' points='165.8671875%2c0 331.734375%2c-165.8671875 165.8671875%2c-331.734375 0%2c-165.8671875'/%3e%3cg transform='translate(-141.8671875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='283.734375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eNeed complex queries or aggregations%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(372.97265625%2c 1429.2421875)' data-id='E' data-node='true' id='flowchart-E-11' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-142.2890625%2c142.2890625)' class='label-container' points='142.2890625%2c0 284.578125%2c-142.2890625 142.2890625%2c-284.578125 0%2c-142.2890625'/%3e%3cg transform='translate(-118.2890625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='236.578125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eKey-based access and ultra fast%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(166.8203125%2c 2068.296875)' data-id='R2' data-node='true' id='flowchart-R2-13' class='node default default flowchart-label'%3e%3crect height='33' width='55.90625' y='-16.5' x='-27.953125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-20.453125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='40.90625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eRedis%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(794.26953125%2c 1807.1640625)' data-id='F' data-node='true' id='flowchart-F-15' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-167.6328125%2c167.6328125)' class='label-container' points='167.6328125%2c0 335.265625%2c-167.6328125 167.6328125%2c-335.265625 0%2c-167.6328125'/%3e%3cg transform='translate(-143.6328125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='287.265625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eAdvanced data structures or algorithms%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(943.2109375%2c 2068.296875)' data-id='R3' data-node='true' id='flowchart-R3-19' class='node default default flowchart-label'%3e%3crect height='51' width='114.59375' y='-25.5' x='-57.296875' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-49.796875%2c -18)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='36' width='99.59375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eDocument DB%3cbr /%3eMongoDB%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(781.828125%2c 1024.4765625)' data-id='G' data-node='true' id='flowchart-G-21' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-194.4765625%2c194.4765625)' class='label-container' points='194.4765625%2c0 388.953125%2c-194.4765625 194.4765625%2c-388.953125 0%2c-194.4765625'/%3e%3cg transform='translate(-170.4765625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='340.953125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eHave SQL expertise and can manage sharding%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(654.14453125%2c 1429.2421875)' data-id='R4' data-node='true' id='flowchart-R4-23' class='node default default flowchart-label'%3e%3crect height='33' width='177.765625' y='-16.5' x='-88.8828125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-81.3828125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='162.765625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eSharded Relational DB%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(909.51171875%2c 1429.2421875)' data-id='H' data-node='true' id='flowchart-H-25' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-116.484375%2c116.484375)' class='label-container' points='116.484375%2c0 232.96875%2c-116.484375 116.484375%2c-232.96875 0%2c-116.484375'/%3e%3cg transform='translate(-92.484375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='184.96875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eSimple key-value access%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(488.21484375%2c 1807.1640625)' data-id='R5' data-node='true' id='flowchart-R5-27' class='node default default flowchart-label'%3e%3crect height='51' width='176.84375' y='-25.5' x='-88.421875' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-80.921875%2c -18)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='36' width='161.84375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eKV Store%3cbr /%3eDynamoDB%2c MongoDB%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1243.3828125%2c 1807.1640625)' data-id='I' data-node='true' id='flowchart-I-29' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-144.0546875%2c144.0546875)' class='label-container' points='144.0546875%2c0 288.109375%2c-144.0546875 144.0546875%2c-288.109375 0%2c-144.0546875'/%3e%3cg transform='translate(-120.0546875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='240.109375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eGraph relationships or traversals%3f%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1265.0234375%2c 2068.296875)' data-id='R6' data-node='true' id='flowchart-R6-31' class='node default default flowchart-label'%3e%3crect height='51' width='86.140625' y='-25.5' x='-43.0703125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-35.5703125%2c -18)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='36' width='71.140625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eGraph DB%3cbr /%3eNeo4j%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Caching
Section titled “Caching”Caches are anything that helps you avoid an expensive network I/o, disk I/o, or cpu computation
- API call to get profile information
- Reading a specific line from a file
- doing multiple table joins
Store frequently accessed data in a temporary storage location to improve performance.
Caching is nothing but a glorified HashMap.
Caching is technique and caches are the places where we store the data.
e.g. Redis (v popular), Mem cached.
Use case
- In my system something that is recently published, will be more accessed e.g. Tweet, YT video, Blog, Recent News, so let me cache it.
- I notices my recommendation system started pushing videos 4 years ago for this channel let me cache it
- Auth Tokens: Authentication are cached in “cache” to avoid load on database when tokens are checked on every requests.
- Live Stream: Last 10 min of Live Stream is cached on CDN, as it will be accessed the most.
Populate Cache
Section titled “Populate Cache”- Mostly logically cache sits between API server and Database
Lazy Population
Section titled “Lazy Population”Populate the cache on demand when data is first requested, or when the cache is accessed, and the data is not present. This is also called “cache aside”.
If the data is requested and not found in the cache, the API server fetches the data from the database, caches it, and then returns it to the client. This approach is simple to implement. The main downside is that the first request for a piece of data will always be slow because it requires a database lookup.
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-A1' id='L-A-A1-0' d='M119.953%2c85.41L124.12%2c85.41C128.286%2c85.41%2c136.62%2c85.41%2c144.07%2c85.41C151.52%2c85.41%2c158.086%2c85.41%2c161.37%2c85.41L164.653%2c85.41'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A1 LE-B' id='L-A1-B-0' d='M262.313%2c85.41L266.479%2c85.41C270.646%2c85.41%2c278.979%2c85.41%2c286.513%2c85.476C294.046%2c85.542%2c300.78%2c85.674%2c304.147%2c85.74L307.514%2c85.806'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-B LE-C' id='L-B-C-0' d='M437.6%2c59.51L453.048%2c51.092C468.496%2c42.673%2c499.393%2c25.837%2c545.609%2c17.418C591.826%2c9%2c653.362%2c9%2c713.788%2c9C774.214%2c9%2c833.529%2c9%2c881.499%2c9C929.469%2c9%2c966.094%2c9%2c996.865%2c9C1027.635%2c9%2c1052.552%2c9%2c1080.998%2c22.702C1109.444%2c36.404%2c1141.42%2c63.807%2c1157.407%2c77.509L1173.395%2c91.211'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-B LE-D' id='L-B-D-0' d='M437.6%2c112.31L453.048%2c120.562C468.496%2c128.814%2c499.393%2c145.317%2c525.172%2c153.645C550.952%2c161.974%2c571.615%2c162.127%2c581.947%2c162.204L592.278%2c162.281'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-D LE-E' id='L-D-E-0' d='M807.109%2c136.211L821.398%2c132.036C835.687%2c127.861%2c864.266%2c119.51%2c887.692%2c115.335C911.119%2c111.16%2c929.394%2c111.16%2c938.531%2c111.16L947.669%2c111.16'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-E LE-C' id='L-E-C-0' d='M1052.469%2c111.16L1056.635%2c111.16C1060.802%2c111.16%2c1069.135%2c111.16%2c1076.585%2c111.16C1084.035%2c111.16%2c1090.602%2c111.16%2c1093.885%2c111.16L1097.169%2c111.16'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-D LE-C' id='L-D-C-0' d='M818.325%2c177.214L830.744%2c178.94C843.164%2c180.666%2c868.004%2c184.118%2c898.736%2c185.844C929.469%2c187.57%2c966.094%2c187.57%2c996.865%2c187.57C1027.635%2c187.57%2c1052.552%2c187.57%2c1079.844%2c178.062C1107.136%2c168.554%2c1136.802%2c149.537%2c1151.636%2c140.029L1166.469%2c130.52'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(892.84375%2c 9)' class='edgeLabel'%3e%3cg transform='translate(-35.125%2c -9)' class='label'%3e%3cforeignObject height='18' width='70.25'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eCache Hit%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(530.2890625%2c 161.8203125)' class='edgeLabel'%3e%3cg transform='translate(-41.7890625%2c -9)' class='label'%3e%3cforeignObject height='18' width='83.578125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eCache Miss%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(59.9765625%2c 85.41015625)' data-id='A' data-node='true' id='flowchart-A-0' class='node default default flowchart-label'%3e%3crect height='33' width='119.953125' y='-16.5' x='-59.9765625' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-52.4765625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='104.953125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eClient Request%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(216.1328125%2c 85.41015625)' data-id='A1' data-node='true' id='flowchart-A1-1' class='node default default flowchart-label'%3e%3crect height='33' width='92.359375' y='-16.5' x='-46.1796875' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-38.6796875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='77.359375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eAPI Server%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(387.90625%2c 85.41015625)' data-id='B' data-node='true' id='flowchart-B-3' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-75.59375%2c75.59375)' class='label-container' points='75.59375%2c0 151.1875%2c-75.59375 75.59375%2c-151.1875 0%2c-75.59375'/%3e%3cg transform='translate(-51.59375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='103.1875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eCache Lookup%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1196.671875%2c 111.16015625)' data-id='C' data-node='true' id='flowchart-C-5' class='node default default flowchart-label'%3e%3crect height='33' width='188.40625' y='-16.5' x='-94.203125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-86.703125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='173.40625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eReturn Data from Cache%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(714.8984375%2c 161.8203125)' data-id='D' data-node='true' id='flowchart-D-7' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-117.8203125%2c117.8203125)' class='label-container' points='117.8203125%2c0 235.640625%2c-117.8203125 117.8203125%2c-235.640625 0%2c-117.8203125'/%3e%3cg transform='translate(-93.8203125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='187.640625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eFetch Data from Database%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1002.71875%2c 111.16015625)' data-id='E' data-node='true' id='flowchart-E-9' class='node default default flowchart-label'%3e%3crect height='33' width='99.5' y='-16.5' x='-49.75' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-42.25%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='84.5'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eCache Data%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
e.g. Caching Blogs
Eager Population
Section titled “Eager Population”Populate the cache proactively, either at the time of data creation or updates, or through a background process that periodically refreshes the cache.
It means pre-loading the caches with the data even before the clients requesting for it. This approach ensures that the data is always available in the cache, resulting in fast reads.
However, it requires more resources, and data in the cache can become stale if not regularly updated.
e.g.
- Some popular person with 1M follower has tweeted, let’s cache all the tweets of this popular person.
- People watching cricket, serve match score from cache
Scaling Technique of Cache
Section titled “Scaling Technique of Cache”- All the things of System Design 1#Scaling Databases applies here as well.
Caching at Different Level
Section titled “Caching at Different Level”- Client Side: Cache is the browser
- e.g. Browser caching - saving static assets like images, CSS, JS files
- Application Side: Inside your code/API server itself
- e.g. Java, Python: using hash maps to cache the results of frequently called functions, or even the whole result of a API call.
- CDN Side: CDN (Content Delivery Network). This is CDN caching.
- e.g. Caching static assets like images, videos, etc.
- Database Side: Cache the result of a query, so that subsequent calls to the same queries does not hit the database.
- e.g. Query caching can be used in databases.
- e.g. Caching indexes, or the results of the queries themselves.
- Precomputed columns Instead of computing total posts by users everytime we store ‘total-posts’ as column and update it once in a while. (saves an expensive DB computation)
Select count (*) from posts where user-id = 123this is an expensive query.- Network Side: Using a proxy cache
- e.g Reverse proxy caching to cache HTTP responses
- Caching on Load Balancer
- Remote /Distributed Cache e.g. Redis
- API server uses it to store frequently served data
Async Processing
Section titled “Async Processing”- Spinning a virtual machine (EC2) can be done asynchronusly. Cause if we wait for 5 mins till it spins up and http request respond me back after that is not good experience.
- Typically long running tasks will be done in async processing.
Message Queues / Brokers
Section titled “Message Queues / Brokers”Brokers help two services applications communicate through messages. We use message brokers whe we want to do something asynchronously.
- Long- running task
- Trigger dependent tasks across machines
Example: Video processing
SQS - Simple Queue Service by Amazon. RabbitMQ - is an open-source message broker.
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-User LE-UploadService' id='L-User-UploadService-0' d='M48.781%2c76.25L60.93%2c76.25C73.078%2c76.25%2c97.375%2c76.25%2c120.789%2c76.25C144.202%2c76.25%2c166.732%2c76.25%2c177.997%2c76.25L189.263%2c76.25'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-UploadService LE-S3' id='L-UploadService-S3-0' d='M318.76%2c59.75L339.218%2c51.292C359.676%2c42.833%2c400.592%2c25.917%2c445.291%2c17.458C489.99%2c9%2c538.471%2c9%2c588.04%2c9C637.609%2c9%2c688.266%2c9%2c742.829%2c9C797.393%2c9%2c855.865%2c9%2c917.82%2c9C979.776%2c9%2c1045.216%2c9%2c1094.852%2c21.155C1144.487%2c33.309%2c1178.318%2c57.619%2c1195.234%2c69.774L1212.149%2c81.928'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-UploadService LE-Broker' id='L-UploadService-Broker-0' d='M318.76%2c92.75L339.218%2c101.208C359.676%2c109.667%2c400.592%2c126.583%2c433.228%2c135.042C465.864%2c143.5%2c490.219%2c143.5%2c502.397%2c143.5L514.575%2c143.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-Broker LE-Worker1' id='L-Broker-Worker1-0' d='M617.164%2c127L637.457%2c115.917C657.75%2c104.833%2c698.336%2c82.667%2c731.894%2c71.583C765.452%2c60.5%2c791.982%2c60.5%2c805.247%2c60.5L818.513%2c60.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-Broker LE-Worker2' id='L-Broker-Worker2-0' d='M654.031%2c143.5L668.18%2c143.5C682.328%2c143.5%2c710.625%2c143.5%2c738.781%2c143.5C766.936%2c143.5%2c794.951%2c143.5%2c808.958%2c143.5L822.966%2c143.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-Broker LE-Worker3' id='L-Broker-Worker3-0' d='M617.164%2c160L637.457%2c171.083C657.75%2c182.167%2c698.336%2c204.333%2c732.636%2c215.417C766.936%2c226.5%2c794.951%2c226.5%2c808.958%2c226.5L822.966%2c226.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-Worker1 LE-S3' id='L-Worker1-S3-0' d='M1004.859%2c60.5L1022.492%2c60.5C1040.125%2c60.5%2c1075.391%2c60.5%2c1109.805%2c65.15C1144.219%2c69.8%2c1177.782%2c79.101%2c1194.564%2c83.751L1211.346%2c88.401'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-Worker2 LE-S3' id='L-Worker2-S3-0' d='M1000.406%2c143.5L1018.781%2c143.5C1037.156%2c143.5%2c1073.906%2c143.5%2c1109.063%2c138.85C1144.219%2c134.2%2c1177.782%2c124.899%2c1194.564%2c120.249L1211.346%2c115.599'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-Worker3 LE-S3' id='L-Worker3-S3-0' d='M1000.406%2c226.5L1018.781%2c226.5C1037.156%2c226.5%2c1073.906%2c226.5%2c1110.166%2c210.776C1146.425%2c195.053%2c1182.195%2c163.605%2c1200.079%2c147.881L1217.964%2c132.158'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg transform='translate(121.671875%2c 76.25)' class='edgeLabel'%3e%3cg transform='translate(-47.890625%2c -9)' class='label'%3e%3cforeignObject height='18' width='95.78125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eUpload Video%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(738.921875%2c 9)' class='edgeLabel'%3e%3cg transform='translate(-59.890625%2c -9)' class='label'%3e%3cforeignObject height='18' width='119.78125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eStore Raw Video%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(441.5078125%2c 143.5)' class='edgeLabel'%3e%3cg transform='translate(-53.3671875%2c -9)' class='label'%3e%3cforeignObject height='18' width='106.734375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eSend Message%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1110.65625%2c 60.5)' class='edgeLabel'%3e%3cg transform='translate(-80.796875%2c -9)' class='label'%3e%3cforeignObject height='18' width='161.59375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eSave Processed Video%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1110.65625%2c 143.5)' class='edgeLabel'%3e%3cg transform='translate(-80.796875%2c -9)' class='label'%3e%3cforeignObject height='18' width='161.59375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eSave Processed Video%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1110.65625%2c 226.5)' class='edgeLabel'%3e%3cg transform='translate(-80.796875%2c -9)' class='label'%3e%3cforeignObject height='18' width='161.59375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eSave Processed Video%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(24.390625%2c 76.25)' data-id='User' data-node='true' id='flowchart-User-0' class='node default default flowchart-label'%3e%3crect height='33' width='48.78125' y='-16.5' x='-24.390625' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-16.890625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='33.78125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eUser%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(278.8515625%2c 76.25)' data-id='UploadService' data-node='true' id='flowchart-UploadService-1' class='node default default flowchart-label'%3e%3crect height='33' width='168.578125' y='-16.5' x='-84.2890625' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-76.7890625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='153.578125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eVideo Upload Service%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1260.421875%2c 102)' data-id='S3' data-node='true' id='flowchart-S3-3' class='node default default flowchart-label'%3e%3cpath transform='translate(-43.96875%2c-31.98649838567655)' d='M 0%2c10.3243322571177 a 43.96875%2c10.3243322571177 0%2c0%2c0 87.9375 0 a 43.96875%2c10.3243322571177 0%2c0%2c0 -87.9375 0 l 0%2c43.3243322571177 a 43.96875%2c10.3243322571177 0%2c0%2c0 87.9375 0 l 0%2c-43.3243322571177' style=''/%3e%3cg transform='translate(-36.46875%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='72.9375'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eS3 Bucket%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(586.953125%2c 143.5)' data-id='Broker' data-node='true' id='flowchart-Broker-5' class='node default default flowchart-label'%3e%3crect height='33' width='134.15625' y='-16.5' x='-67.078125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-59.578125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='119.15625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eSQS / RabbitMQ%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(914.3359375%2c 60.5)' data-id='Worker1' data-node='true' id='flowchart-Worker1-7' class='node default default flowchart-label'%3e%3crect height='33' width='181.046875' y='-16.5' x='-90.5234375' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-83.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='166.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eVideo Processor 1080p%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(914.3359375%2c 143.5)' data-id='Worker2' data-node='true' id='flowchart-Worker2-9' class='node default default flowchart-label'%3e%3crect height='33' width='172.140625' y='-16.5' x='-86.0703125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-78.5703125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='157.140625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eVideo Processor 720p%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(914.3359375%2c 226.5)' data-id='Worker3' data-node='true' id='flowchart-Worker3-11' class='node default default flowchart-label'%3e%3crect height='33' width='172.140625' y='-16.5' x='-86.0703125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-78.5703125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='157.140625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eVideo Processor 480p%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Features
Section titled “Features”- Brokers help us connect diferent sub-systems
- Brokers act as a buffer for the messages/tasks
- i.e. Service can add as many things as they want to delegate to system, it will put it in queue and worker will pick it from there, when they are free.
- Brokers can retain messages far ‘n’ days. It is configurable though.
- SQS offers 14 days of maximum days, after that it will expire
- Brokers can re-queue the message if not deleted
- Let say you picked a email sending job from queue, while processing it crashed, and it failed to delete the job from queue. Now after some time queue we automatically reque it. - It’s Visibility Time out on SQS
SQS Core API Actions
Section titled “SQS Core API Actions”These actions facilitate the core message lifecycle: sending, receiving, and deleting messages.
CreateQueue: This action is used to create a new message queue. You can specify parameters likeQueueName, choose between a Standard or FIFO (First-In-First-Out) queue typeSendMessage: This is how producer components introduce messages into the queue. A developer provides the queue’s URL and the message body. In FIFO queues, this action might also involve specifying aMessageDeduplicationIdfor exactly-once processing guarantees.ReceiveMessage: Consumer components call this action to retrieve messages from the queue. When a message is received, it isn’t immediately deleted; instead, it becomes temporarily invisible to other consumers for aVisibilityTimeoutperiod, allowing the current consumer time to process it.DeleteMessage: After a consumer successfully processes a message, it must call this action using the uniqueReceiptHandleprovided during theReceiveMessagecall. This is the crucial step that prevents the message from being processed again when the visibility timeout expires.
RabbitMQ in 100 Seconds by Fireship
Message Streams
Section titled “Message Streams”Apache kafka - Most popular AWS Kinesis is another example
- Similar to message queues, but designed for high-throughput, real-time data streaming to multiple different clients
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-B' id='L-A-B-0' d='M79.922%2c58L84.089%2c58C88.255%2c58%2c96.589%2c58%2c104.039%2c58C111.489%2c58%2c118.055%2c58%2c121.339%2c58L124.622%2c58'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-B LE-C' id='L-B-C-0' d='M217.461%2c41.5L225.545%2c37.333C233.63%2c33.167%2c249.799%2c24.833%2c261.167%2c20.667C272.535%2c16.5%2c279.102%2c16.5%2c282.385%2c16.5L285.669%2c16.5'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-B LE-D' id='L-B-D-0' d='M217.461%2c74.5L225.545%2c78.667C233.63%2c82.833%2c249.799%2c91.167%2c261.167%2c95.333C272.535%2c99.5%2c279.102%2c99.5%2c282.385%2c99.5L285.669%2c99.5'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(39.9609375%2c 58)' data-id='A' data-node='true' id='flowchart-A-0' class='node default default flowchart-label'%3e%3crect height='33' width='79.921875' y='-16.5' x='-39.9609375' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-32.4609375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='64.921875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eProducer%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(185.4453125%2c 58)' data-id='B' data-node='true' id='flowchart-B-1' class='node default default flowchart-label'%3e%3crect height='33' width='111.046875' y='-16.5' x='-55.5234375' ry='5' rx='5' style='' class='basic label-container'/%3e%3cg transform='translate(-48.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='96.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eKafka Cluster%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(366.5%2c 16.5)' data-id='C' data-node='true' id='flowchart-C-3' class='node default default flowchart-label'%3e%3crect height='33' width='151.0625' y='-16.5' x='-75.53125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-68.03125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='136.0625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eConsumer Group 1%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(366.5%2c 99.5)' data-id='D' data-node='true' id='flowchart-D-5' class='node default default flowchart-label'%3e%3crect height='33' width='151.0625' y='-16.5' x='-75.53125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-68.03125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='136.0625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eConsumer Group 2%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Apache Kafka allows us to organize data into topics, with each topic having multiple partitions for parallel read/write operations. Consumers read data from these topics, and multiple consumer groups can independently process the same data streams.
%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%2c%23mermaid-0 p%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='6' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='12' markerWidth='12' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart' id='mermaid-0_flowchart-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart' id='mermaid-0_flowchart-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'%3e%3cg id='subGraph0' class='cluster default flowchart-label'%3e%3crect height='164.5' width='193.65625' y='0' x='437.78125' ry='0' rx='0' style=''/%3e%3cg transform='translate(486.5859375%2c 0)' class='cluster-label'%3e%3cforeignObject height='18' width='96.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eKafka Cluster%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-A LE-B' id='L-A-B-0' d='M103.047%2c87.25L107.214%2c87.25C111.38%2c87.25%2c119.714%2c87.25%2c127.247%2c87.316C134.781%2c87.382%2c141.514%2c87.514%2c144.881%2c87.58L148.248%2c87.646'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-B LE-KafkaTopic' id='L-B-KafkaTopic-0' d='M293.125%2c87.75L305.138%2c87.667C317.151%2c87.583%2c341.177%2c87.417%2c365.286%2c87.333C389.396%2c87.25%2c413.589%2c87.25%2c428.968%2c87.25C444.348%2c87.25%2c450.915%2c87.25%2c454.198%2c87.25L457.481%2c87.25'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-KafkaTopic LE-EmailService' id='L-KafkaTopic-EmailService-0' d='M573.107%2c70.75L582.829%2c66.583C592.551%2c62.417%2c611.994%2c54.083%2c635.665%2c49.917C659.336%2c45.75%2c687.234%2c45.75%2c716.251%2c45.75C745.267%2c45.75%2c775.402%2c45.75%2c790.469%2c45.75L805.536%2c45.75'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-KafkaTopic LE-AnalyticsService' id='L-KafkaTopic-AnalyticsService-0' d='M573.107%2c103.75L582.829%2c107.917C592.551%2c112.083%2c611.994%2c120.417%2c635.665%2c124.583C659.336%2c128.75%2c687.234%2c128.75%2c714.249%2c128.75C741.265%2c128.75%2c767.396%2c128.75%2c780.462%2c128.75L793.528%2c128.75'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-EmailService LE-SES' id='L-EmailService-SES-0' d='M923.648%2c45.75L940.859%2c45.75C958.07%2c45.75%2c992.492%2c45.75%2c1024.029%2c45.75C1055.567%2c45.75%2c1084.219%2c45.75%2c1098.546%2c45.75L1112.872%2c45.75'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-pointEnd)' style='fill:none%3b' class='edge-thickness-normal edge-pattern-solid flowchart-link LS-AnalyticsService LE-DataWarehouse' id='L-AnalyticsService-DataWarehouse-0' d='M935.656%2c128.75L950.866%2c128.75C966.076%2c128.75%2c996.495%2c128.75%2c1028.671%2c128.75C1060.848%2c128.75%2c1094.782%2c128.75%2c1111.749%2c128.75L1128.716%2c128.75'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(365.203125%2c 87.25)' class='edgeLabel'%3e%3cg transform='translate(-47.578125%2c -9)' class='label'%3e%3cforeignObject height='18' width='95.15625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eUser Created%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(715.1328125%2c 45.75)' class='edgeLabel'%3e%3cg transform='translate(-58.6953125%2c -9)' class='label'%3e%3cforeignObject height='18' width='117.390625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eEmail Campaign%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(715.1328125%2c 128.75)' class='edgeLabel'%3e%3cg transform='translate(-58.6953125%2c -9)' class='label'%3e%3cforeignObject height='18' width='117.390625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eAnalytics Events%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1026.9140625%2c 45.75)' class='edgeLabel'%3e%3cg transform='translate(-48.9140625%2c -9)' class='label'%3e%3cforeignObject height='18' width='97.828125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eSends Emails%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1026.9140625%2c 128.75)' class='edgeLabel'%3e%3cg transform='translate(-66.2578125%2c -9)' class='label'%3e%3cforeignObject height='18' width='132.515625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3eCompute Analytics%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(534.609375%2c 87.25)' data-id='KafkaTopic' data-node='true' id='flowchart-KafkaTopic-3' class='node default default flowchart-label'%3e%3crect height='33' width='143.65625' y='-16.5' x='-71.828125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-64.328125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='128.65625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eUser Events Topic%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(51.5234375%2c 87.25)' data-id='A' data-node='true' id='flowchart-A-0' class='node default default flowchart-label'%3e%3crect height='33' width='103.046875' y='-16.5' x='-51.5234375' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-44.0234375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='88.046875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eUser Signup%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(222.8359375%2c 87.25)' data-id='B' data-node='true' id='flowchart-B-1' class='node default default flowchart-label'%3e%3cpolygon style='' transform='translate(-69.7890625%2c69.7890625)' class='label-container' points='69.7890625%2c0 139.578125%2c-69.7890625 69.7890625%2c-139.578125 0%2c-69.7890625'/%3e%3cg transform='translate(-45.7890625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='91.578125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eUser Service%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(867.2421875%2c 45.75)' data-id='EmailService' data-node='true' id='flowchart-EmailService-5' class='node default default flowchart-label'%3e%3crect height='33' width='112.8125' y='-16.5' x='-56.40625' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-48.90625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='97.8125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eEmail Service%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(867.2421875%2c 128.75)' data-id='AnalyticsService' data-node='true' id='flowchart-AnalyticsService-7' class='node default default flowchart-label'%3e%3crect height='33' width='136.828125' y='-16.5' x='-68.4140625' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-60.9140625%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='121.828125'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eAnalytics Service%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1201.25%2c 45.75)' data-id='SES' data-node='true' id='flowchart-SES-9' class='node default default flowchart-label'%3e%3crect height='33' width='166.15625' y='-16.5' x='-83.078125' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-75.578125%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='151.15625'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eSimple Email Service%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(1201.25%2c 128.75)' data-id='DataWarehouse' data-node='true' id='flowchart-DataWarehouse-11' class='node default default flowchart-label'%3e%3crect height='33' width='134.46875' y='-16.5' x='-67.234375' ry='0' rx='0' style='' class='basic label-container'/%3e%3cg transform='translate(-59.734375%2c -9)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='18' width='119.46875'%3e%3cdiv style='display: inline-block%3b white-space: nowrap%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3eData Warehouse%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
The User Service publishes “User Created” events to a Kafka topic. Both the Email Service and Analytics Service subscribe to this topic, enabling real-time email campaigns and analytics updates.
Difference between Kafka vs SQS
Section titled “Difference between Kafka vs SQS”- In SQS (Message Broker) - While multiple consumers can poll the queue, any given message is intended to be processed by only one receiver at a time i.e *Single-Message Processing once
- But in case of Apache Kafka - Multiple consumer groups can independently process the same data streams i.e single-message processing by multiple different services.
- SQS is more suited for task queue